Upon receiving a FASTQ file fresh off the MiSeq, the first question I ask myself is: "Did the sequencing work?" On several occasions I open these files to discover the first few pages of sequence reads are littered with N's and have low quality scores. However, when I run the full set of reads through a QC pipeline (e.g. FastQC) an overwhelming majority are high quality.
So why is it that the reads at the beginning of the FASTQ file have such poor quality?
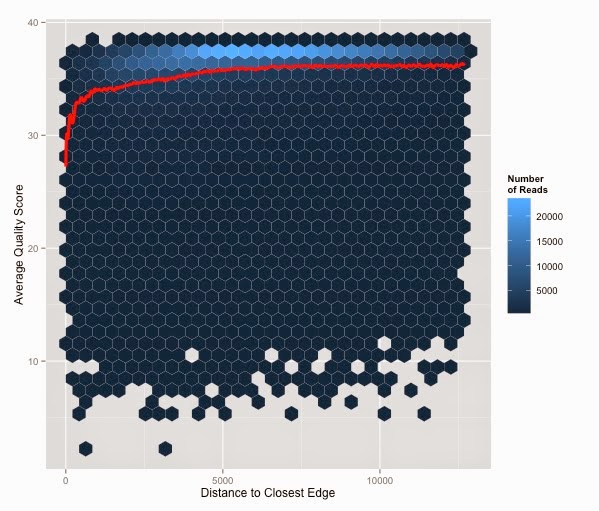
Reads generated using Illumina technology are ordered by their cluster's y-coordinate on the flow cell. This led me to hypothesize that clusters near the edge of the flow cell are more likely to have low quality scores. To test this hypothesis I took a subset of reads (932,709) from a MiSeq run, calculated their average quality score, and graphed that against the distance from the closest edge.
So why is it that the reads at the beginning of the FASTQ file have such poor quality?
Reads generated using Illumina technology are ordered by their cluster's y-coordinate on the flow cell. This led me to hypothesize that clusters near the edge of the flow cell are more likely to have low quality scores. To test this hypothesis I took a subset of reads (932,709) from a MiSeq run, calculated their average quality score, and graphed that against the distance from the closest edge.
The splines function in R was used to model the relationship between average quality score and distance from the closest flow cell edge (red line). Clusters closer to the edge of the flow cell have significantly lower quality scores. However, the good news is that the vast majority of clusters do not fall close to the edge (light blue heat).
In practical terms this issue is insignificant because so few reads are affected, but it does explain the high concentration of low quality reads at the beginning (and end) of Illumina generated FASTQ files.
No comments:
Post a Comment